Relacionamento no MongoDB ? WTF
Relacionamentos entre collections, explain, replicas, índices, rand, e GridFS.
Relacionamento ?

Não! Não é esse tipo de relacionamento, e sim de banco de dados. =(
Nos banco relacionais é de fato o uso de joins pra relacionar uma tabela com outra, porém como funciona o relacionamento no MongoDB ? Joins não existem no MongoDB, não tem como fazer a busca automática de duas coleções separadas usando alguma chave estrangeira como nos relacionais. Existe duas formas, a Manual e DBRef. Já que a forma Manual é a mais usada, vamos ver como funciona.
Relacionamento Manual
Salve o _id de uma coleção em outra, por exemplo: 1º vamos pegar 3 _id de pokemons da nossa collection pokemons que já havíamos trabalho (caso ainda não tenha a collection pokemons use o pokemons.json
> db.pokemons.find().limit(3)"_id": ObjectId("564a7c362c153ed825a69054")
"_id": ObjectId("564a7c362c153ed825a69055")
"_id": ObjectId("564a7c362c153ed825a69056")Crie um array de pokemons com esses ids para adicionar no nosso inventário de pokemons:
var pokemons = [
{"_id": ObjectId("564a7c362c153ed825a69054")},
{"_id": ObjectId("564a7c362c153ed825a69055")},
{"_id": ObjectId("564a7c362c153ed825a69056")}
];Agora crie um JSON para ser inserido no inventário:
var json = {name: "meus pokemons", pokemons: pokemons}No pokemons:pokemons o pokemons é um array de pokemons (aquele que criamos logo ali em cima).
Inserindo no inventário
db.invt.insert(json)
Inserted 1 record(s) in 80ms
WriteResult({
"nInserted": 1
})Conferindo:
> db.invt.find()
{
"_id": ObjectId("568c969d2622b96d939ca206"),
"name": "meus pokemons",
"pokemons": [
{
"_id": ObjectId("564a7c362c153ed825a69054")
},
{
"_id": ObjectId("564a7c362c153ed825a69055")
},
{
"_id": ObjectId("564a7c362c153ed825a69056")
}
]
}Pegando todos os dados a partir do id
Pra fazer isso vamos criar uma função que recebe o _id e insere em um array todos os dados dos pokemons.
var pokemons = [];
var getPokemon = function (id){
pokemons.push(db.pokemons.findOne(id))
}
var invt = db.invt.findOne()
invt.pokemons.forEach(getPokemon)Cuidado, o invt.pokemons é aquele que inserimos, onde possui todos os 3 ids, a variável criada chamada pokemons é o array onde vai ser inserido todos os dados dos pokemons através da função getPokemon, pois nela contém um pokemons.push que insere cada resultado do db.pokemons.findOne(). Repare que agora a variável pokemons está com todos os dados dos id:
[
{
"_id": ObjectId("564a7c362c153ed825a69054"),
"attack": 90,
"created": "2013-11-03T15:05:41.297180",
"defense": 40,
"height": "10",
"hp": 65,
"name": "Beedrill",
"speed": 75,
"types": [
"poison",
"bug"
]
},
{
"_id": ObjectId("564a7c362c153ed825a69055"),
"attack": 45,
"created": "2013-11-03T15:05:41.299457",
"defense": 40,
"height": "3",
"hp": 40,
"name": "Pidgey",
"speed": 56,
"types": [
"normal",
"flying"
]
},
{
"_id": ObjectId("564a7c362c153ed825a69056"),
"attack": 60,
"created": "2013-11-03T15:05:41.301609",
"defense": 55,
"height": "11",
"hp": 63,
"name": "Pidgeotto",
"speed": 71,
"types": [
"normal",
"flying"
]
}
]DBRef
obs: para não deixar de lado o DBRef, é importante saber como funciona.
A outra forma é o DBRef, uma convenção pra representar um documento relacional, ou seja,semelhantes a chave estrangeira vista em banco relacionais.
- $ref: nome da coleção a ser referenciada.
- $id: o ObjectId do documento referenciado.
- $db: a database onde a coleção referenciada se encontra.
Pelo fato de conseguir referenciar seus documentos que estão em outra database, nesse caso é interessante usar o DBRef.
Explain
O que é o Explain ? Ele nos mostra como o MongoDB executa as query internamente.
db.pokemons.find({"name": "Meloetta-aria"}).explain()Vai retornar algumas informações, como por exemplo o serverInfo que nos mostra o host em que ele pegou, a porta, versão, etc…
Se colocarmos executionStats, vai nos mostrar além da padrão, informações de execução.
db.pokemons.find({"name": "Meloetta-aria"}).explain('executionStats')Repare que temos por exemplo o executionTimeMillis, que nos mostra o tempo em milissegundo, e o docsExamined, que nos retorna quantos documentos foram examinados, ou seja, procurando com essa query a cima, ele varreu toda nossa base pra poder encontrar o Meloetta-aria.
Quando usar o Explain ?
Sempre que queremos analisar o que ele fez, a partir dessas e outras informações que ele nos dá.
Index
Os índices são importantes, com ele tem como ‘marcar’ uma determinada propriedade que estamos sempre buscando, e quando eu buscar ele, execute mais rápido. Por padrão o mongo que cria os _id não é ? não apenas, como também são indexados, e para que saiba que não estou mentindo ‘–’ execute:
db.pokemons.getIndexes()
//resultado:
[
{
"v": 1,
"key": {
"_id": 1 //<-- significa que o _id está indexado
},
"name": "_id_",
"ns": "be-mean-pokemons.pokemons"
}
]E se você buscar pelo _id e não pelo nome e em seguida usar explain para saber a quantidade de elementos verificados, vai perceber que só foi 1, isso mesmo é magia , com isso a busca ficou muito mais rápida. Agora você sabe o porquê existe aquele system.indexes quando listamos as collections, pois ele deixa tudo mapeado.
Como criar um index ?
Repare que nas collections, já vem o _id indexado.
db.system.indexes.find()Pra você indexar o nome por exemplo, crie:
db.pokemons.createIndex({name:1}) //onde o parâmetro é o nome e a ordem
//para descrescente coloque -1Agora a pesquisa pelo nome ficou muito mais rápida: ٩(●̮̮̃•̃)۶
E se eu não quero mais que o nome fique indexado ?
db.pokemons.dropIndex({nome: 1})Observação: Tome cuidado com os index, não fique criando index pra qualquer coisa, sempre que criar, seu banco fica mais complexo, pois ele precisa guardar, verifique sempre se realmente precisa na hora de criar.
Rand
Rand é uma função que retorna um número aleatório, por exemplo queremos pegar dois pokemons qualquer:
db.pokemons.find().limit(2).skip(_rand() * db.pokemons.count())GridFS
Ele é um sistema de arquivos, e com ele você pode salvar arquivos binário. Por exemplo, um vídeo, imagem, ou música.
Por que usar ?
Você pode não querer usar o GridFS e salvar em um arquivo BJSON, mas só que sabemos que um documento desse tem um limite de 16MB =( Se quer enviar um vídeo de 40MB por exemplo, o GridFS ta ae pra nos ajudar com isso.
Acesse esse artigo para saber quando usar o GridFS no MongoDB.
Como usar ?
Entre no terminal (não do mongo), pois é um binário. Para inserir na database, vá até onde o seu vídeo está, e execute
mongofiles -d nome-do-banco -h 127.0.0.1 put nomedoarquivoPronto, agora entre no terminal do mongo e veja as coleções do banco em que inseriu o video, vai perceber que tem duas. São:
fs.chunk: Fica o arquivo binário quebrado em pequenas partes de 255KB. Cada parte tem o seu, _id, files _id, n(o índice nesse arquivo quebrado) e data(o binário).
fs.files: Guarda as informações dos arquivos, como o _id o tamanho deste arquivo, nome do arquivo, etc.
Aprenda na prática com:
Building MongoDB Applications with Binary Files Using GridFS: Part 1
Building MongoDB Applications with Binary Files Using GridFS: Part 2
Replica
É basicamente um espalhamento dos seus dados em outro servidor, e no MongoDb uma ReplicaSet pode ter 50 replicas. oloco :0
Diagrama:
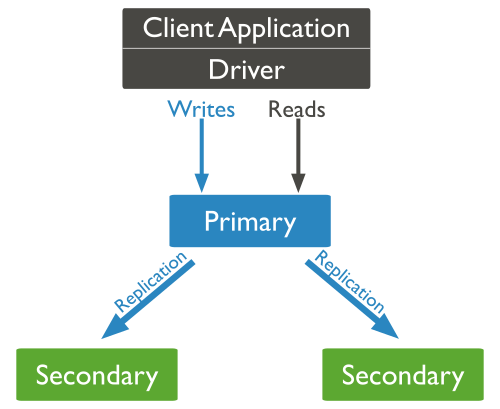
As 2 estapas que ocorrem na replicação são:
Initial Sync: Aconte quando a replicação inicia, ela clona todos os bancos de dados, depois ele aplica as alterações, contróis os índices de todas as coleções e por fim, ele faz a transição pro secundário, como na imagem a cima.
Replication: Depois de ter os dados na replica secundária, vai continuar replicando, sicronizando para deixar sempre atualizado, caso faça alguma modificação na primária, acontecendo de forma assícrono.
OpLog
O OpLog é simplesmente um log de alteração, mantém todas as modifições na capped collection, e ele tem um tamanho fixo, caso ultrapasse ele sobrescreve.(Mais pra frente vamos ver como saber o tamanho)
Por que usar Replica ?
Para garantir que seus dados ficam em lugares além do servidor principal, aliás qualquer sistema o próprio mongodb diz para ter no mínimo uma replica, seja simples que for, garanta a segurança nos seus dados, nenhum servidor é 100% seguro.
Como criar ?
Abra o terminal e execute, para quantas replicas quer.
mongodb --replSet replica_set --port 27017 --dbpath localparasalvarDepois conecte em cada uma para iniciar o serviço de replica com o rs.initialize() e para isso precisamos criar um JSON de configuração da nossa replica:
rsconfig = {
_id: "replica_set",
members:[
{
_id:0,
host: "127.0.0.1:27017"
}
]
}
rs.initialize(rsconfig)Resultado:
{
"ok": 1
}Agora tá iniciando (lembra do init sync logo ali em cima ?). Agora levantado, não precisamos desse trabalho todo para adicionar as outras replicas que queira =)
Basta usar um add, pra adicionar.
rs.add("127.0.0.1:27018"); //coloquei 27018, mas você coloca o da sua replicaObservação: Você não pode executar nenhum comando nos secundários, apenas no primário.
Para verificar o status da nossa replicaSet basta executar rs.status( ), e com isso você verifica várias informações como o nome de todas as replicas, id, data, etc.
E para o status do nosso OpLog, é rs.printReplicationInfo( ) e então informações como o do tamanho do nosso OpLog, info da primeira modificação, e info da última vez que foi feito alguma modificação. Saiba mais sobre Replicas na documentação
Concluindo
E claro não deixe de ler:
Como mudar seu jeito relacional de pensar - Parte 1
Como mudar seu jeito relacional de pensar - Parte 2
Model Relationships Between Documents
E é isso, até a próxima, bye! =)